Set up a Google Cloud Service data destination to export data from Singular automatically to GCS.
Note: Data destinations are an enterprise feature (learn more).
Setup Instructions
1. Obtain a Service Account
Option A: Create a New Service Account (Recommended)
- In the Google Cloud platform, go to IAM & Admin > Service Accounts and click Create Service Account.
-
Enter a name, an ID, and a description for the service account and click Create.

-
To create a JSON key for the account, click Create Key. Under Key Type, choose "JSON", and click Create.

- Download the key file and keep it - you will need to upload it to Singular in step 3 below.
Option B: Use Singular's Existing Service Account
You can use Singular's existing account: singular-etl@singular-etl.iam.gserviceaccount.com. You will grant this account the necessary permissions in step 3 below.
2. Create a New Bucket
To create a bucket:
- In the Google Cloud Platform dashboard, go to the Storage section and click Create Bucket.
-
Pick a name for the bucket. We recommend picking a name that indicates that this bucket is for Singular's data destination (ETL).

-
Under Choose where to store your data, select your preferred location. If you don't have a specific preference, we recommend using the default options of "Multi-region" and "us".
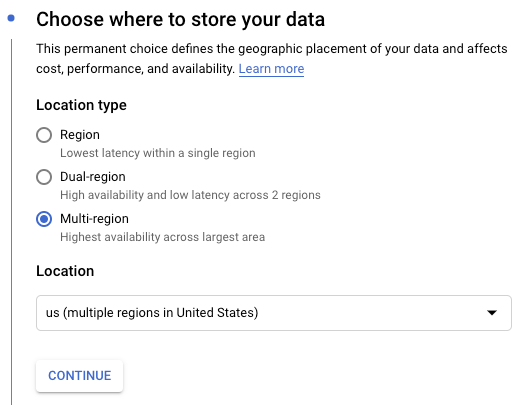
-
Under Choose a default storage class for your data, select "Standard" (your data will be accessed several times a day).
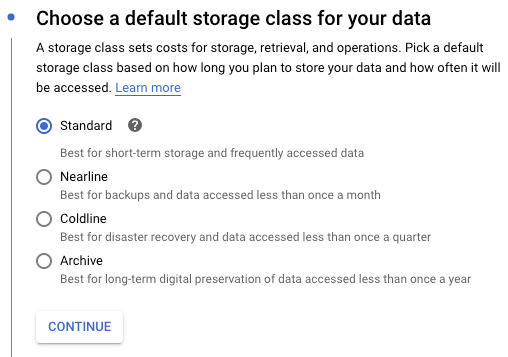
-
Under Choose how to control access to objects, select "Fine-grained".
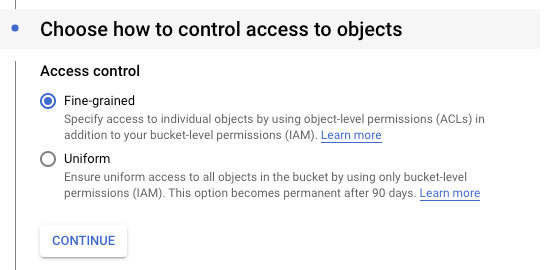
- Under Advanced Settings, leave all the default options unchanged, and click Create.
3. Grant Permissions
After creating the bucket:
-
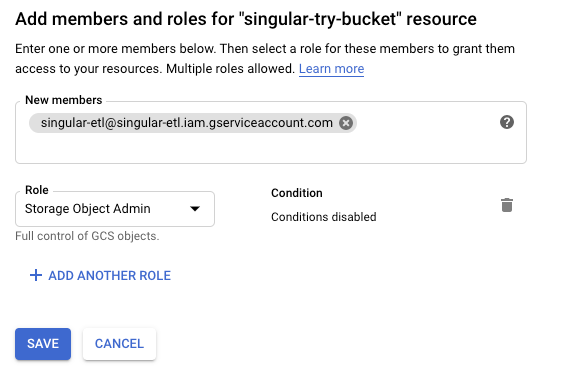
Switch to the Permissions tab and click Add members.

- If you chose to use Singular’s existing GCS account, enter the following email address: singular-etl@singular-etl.iam.gserviceaccount.com. Otherwise, use your own account that you have created in section #2.
-
Under Add members and roles, select the role "Storage Object Admin". This allows Singular to write files, delete files, and check if any files exist in the bucket.
4. Add a GCS Data Destination
Finally, to add a GCS data destination in Singular:
- In your Singular account, go to Settings > Data Destinations and click Add a new destination.
- Type in either "GCS Destination" (to export aggregated marketing data) or "GCS User-Level Destination" (to export user-level data).
-
In the window that opens, fill in the relevant details:
Field Description Bucket Name Enter the Bucket name from Step #2. Service Account Type Choose the appropriate service account type (user-created or Singular's pre-made) based on Step #1. Credentials File Upload the file you created in Step #1, wouldn't show if you chose to give access to Singular's pre-made Service Account. Output File Format Select an output format: "CSV" or "Parquet". Data Schema The schema of the data loaded into the destination. For your schema options, see Data Destinations: Aggregated Marketing Data Schemas and Data Destinations: User-Level Data Schemas. Output Key Pattern The format of the file name to create. See the table below for optional placeholders you can use.
Singular supports several placeholders (macros) that will get expanded automatically:
| Placeholder | Description | Example |
| {date} | Date of the data being exported from Singular | 2020-03-19 |
| {day} | The day part of the data being exported from Singular (zero-padded) | 19 |
| {month} | The month part of the data being exported from Singular | 03 |
| {year} | The year part of the data being exported from Singular | 2020 |
| {extension} | Output file extension | .csv or .parquet |
| {job_timestamp} | The exact time the ETL job started running. Use this if you would like to have a new file every day (for example, have a new folder for each run with all the dates that were pulled in that job). | 2020-03-20 16:12:34 |
| {job_date} | The date the ETL job started running. Similar to {job_timestamp}, but contains only the date of the job rather than the full timestamp. | 2020-03-20 |